Apprendre de l’apprentissage automatique
Sylvia Lavin réfléchit aux arbres modélisés et aux historiographies architecturales du numérique
Que signifie pour les chercheurs de collaborer avec les machines de connaissance contemporaines? Dans cet article, Sylvia Lavin réfléchit aux échecs, aux succès et aux potentialités d’un outil d’apprentissage automatique conçu pour identifier les arbres dans les dessins d’architecture. Ce projet, qu’elle a initié en 2022, entrepris par Princeton University et le CCA et avec la participation de Drawing Matter, a été soutenu par le Princeton University Humanities Council Magic Grant. Cet article est publié conjointement avec Drawing Matter.

Identification d’arbres par un outil de machine apprenante dans Ernest Born (1898 – 1992), Maquette d’une maison citadine, pour une exposition au San Francisco Museum of Art, 1937. Photographie de la maquette collée sur passe-partout, 385 x 355 mm. DMC 2320.3. Avec l’aimable autorisation de Drawing Matter Collections © Estate of Ernest and Esther Born
La question du calcul par ordinateur en architecture fait l’objet d’une littérature scientifique de plus en plus étoffée : au cours des dix dernières années, ce corpus de nouveaux travaux a élargi les préoccupations des années 1990, qui théorisaient la conception numérique des formes, puis se sont ensuite intéressées à la fabrication et à la construction, à des questions plus spécifiquement historiques relatives à l’impact du numérique sur les développements globaux de l’écologie technosociale de l’architecture. Les spécialistes de l’histoire de l’architecture, comme toutes les personnes qui travaillent aujourd’hui dans la recherche, sont de plus en plus sujets à la domination croissante des protocoles de recherche numérique, accélérée par les nombreux projets de numérisation mis en place pour faire face aux limitations de l’accès physique aux archives et aux bibliothèques liées à la pandémie de COVID. Aujourd’hui, les fichiers PDF, la numérisation, la recherche Google et les logiciels de reconnaissance optique de caractères étayent les méthodes de recherche d’universitaires dont les intérêts et les positions idéologiques diffèrent par ailleurs. Toutefois, malgré cette omniprésence évidente et la montée en puissance des humanités numériques sur les campus universitaires, l’attention expressément portée par les spécialistes de l’histoire de l’architecture à la présence du numérique dans leur propre travail s’est largement cristallisée sur les questions, de plus en plus convergentes, de la publication et de la gestion des données. Les plateformes de publication en ligne et les projets d’archivage financés de manière participative (souvent une seule et même chose), collectent et fournissent l’accès à des données en tant que travail intellectuel, mais transfèrent généralement le traitement de l’information à d’autres.
La rapide consolidation des possibilités du calcul par ordinateur pour l’histoire de l’architecture en termes de diffusion et de mégadonnées ne doit pas pour autant empêcher d’envisager comment un éventail plus diversifié de présences numériques au sein de l’histoire de l’architecture pourrait contribuer à l’écologie créative de ce domaine. C’est dans cette optique que ce projet, fruit d’une collaboration entre Princeton University et le Centre Canadien d’Architecture, et avec la participation de Drawing Matter, a développé un outil d’apprentissage automatique conçu pour identifier les arbres dans les dessins d’architecture1. Il s’agissait d’expérimenter l’utilisation d’outils numériques pour troubler les conventions d’organisation et de catalogage des dessins dans les archives et les « collections » et de mettre à jour la technique de l’« interprétation visuelle », autrefois activité essentielle, mais contestée de la personne spécialiste de l’histoire de l’architecture, et désormais méthode encore courante, bien que de moins en moins théorisée. Tandis que le fait de fournir du matériel à d’autres pour l’activer évoque les approches de l’information caractéristiques des premiers jours du World Wide Web, à savoir le Whole Earth Catalog ou Global Tools, le report a ses propres limites éthiques, liées à la réalité empirique du délai et à la supposition non empirique de l’objectivité. Plutôt que la neutralité, ce projet a donc été conçu comme une initiative visant à reformuler activement les relations entre les choses dans le monde.
Pour cette expérience, le « dessin » est défini prosaïquement et tautologiquement comme tout ce qui est considéré comme un dessin et disponible sous forme de fichier d’image numérique dans les collections du CCA et de Drawing Matter. Ce choix intervient dans le contexte d’une tendance à faire du « document » un objet d’étude privilégié pour les spécialistes de l’histoire de l’architecture, considéré comme un dérivé artéfactuel de la critique des structures de pouvoir, inscrites à la fois dans la catégorie historique du dessin d’architecture auctorial et dans l’expertise requise pour le lire2. C’est précisément en raison de cette contamination que les dessins sont profondément et visiblement liés à la manière dont l’architecture a défini l’humanité (la nécessité de contrecarrer la tendance humaine à être séduit par les images et leurs simulacres, par exemple, est intégrée dans l’injonction de la profession contre la perspective; tandis que la capacité du dessin d’architecture à introduire subrepticement une personnalité et une subjectivité autonomes dans un ensemble d’opérations, par ailleurs déterminées de manière industrielle a souvent été soulignée). Ainsi, libérer le machinique dans le domaine anthropomorphisant du dessin semblait constituer une bonne approche pour imaginer des formes plus variées d’engagement, et même de collaboration, entre les spécialistes et les conditions numériques de leur travail.
Les « arbres », définis comme des dessins, en termes tout aussi prosaïques de plantes boisées, ont été choisis pour leur rôle d’interface épistémique entre les êtres humains et les non-humains depuis au moins l’ère biblique; lorsque Ève goûte l’arbre de la connaissance, elle amorce la construction du monde dans lequel réside l’architecture. En tant que sujets, les arbres permettent donc de supposer que leur présence dans un dessin opère un travail épistémologique, ce qui en fait des alibis essentiels pour un projet d’apprentissage automatique. Parallèlement, en partie à cause de cette tradition qui privilégie le registre arboricole des formes de vie du monde, l’omniprésence des arbres dans les dessins d’architecture est si manifestement inhérente à la représentation de l’environnement qu’ils ont rarement été intégrés aux types de métadonnées qui permettent aux spécialistes de se repérer dans le nombre de plus en plus important de dessins constituant une strate substantielle des archives de ce domaine3. Les arbres sont donc paradoxalement omniprésents tout en étant invisibles dans les dessins d’architecture, où ils accomplissent un travail épistémique spécifique qui repose sur des techniques de dessin telles que le calcul des proportions, la détermination de l’impact du soleil sur la terre et la prise en compte du développement de la science des sols et du bois d’œuvre dans les procédures de construction. Plus important encore, étant donné que leur rôle sous-jacent dans la structuration de la représentation architecturale vise à naturaliser des opérations épistémiques significatives, les arbres ont généralement perturbé les conventions du dessin; ils apparaissent souvent en projection isométrique, par exemple, dans des images qui sont par ailleurs dessinées en plan, ou sous forme de protubérances en perspective sur des élévations sinon planes.
Chacune de ces distorsions, paradoxes et exceptions laissait présager que l’outil d’apprentissage automatique ne parviendrait pas à accomplir la simple tâche d’identification des arbres présents dans les dessins d’architecture. L’échec était d’autant plus prévisible que le nombre de dessins accessibles numériquement via le CCA et Drawing Matter, même combinés, était bien inférieur par un facteur de plusieurs milliers au nombre d’échantillons de contrôle habituellement utilisés comme ensembles d’entraînement, et ce même lorsque les machines cherchent à apprendre des leçons assez élémentaires. Certaines dimensions de la discipline sont donc trop petites pour être saisies par les dispositifs numériques, fait qu’il semble essentiel de signaler pour les risques qu’il pose, mais plus encore pour les avantages qu’il peut apporter. Néanmoins, et malgré un certain degré d’échec d’un point de vue informatique, l’outil a permis d’obtenir plusieurs résultats instructifs, y compris le repérage d’arbres que je n’aurais pas identifiés autrement.
De mon point de vue, la possibilité pour les spécialistes d’éviter de surdéterminer le catalogue et les rubriques thématiques lors de la recherche de documents constitue une amélioration significative du processus de recherche. Contrairement aux mesures quantifiables recherchées par les spécialistes du codage, cet avantage ne repose pas sur l’exactitude absolue des résultats; quelques surprises peuvent suffire à ouvrir de nouvelles voies de recherche. De même, l’inclusion des dessins dans les procédures de « numérisation » que les spécialistes mettent en œuvre lors de la constitution d’archives de recherche sur l’histoire de l’architecture, qu’elles soient basées sur la numérisation OCR de documents, le feuilletage manuel et la lecture rapide de pièces administratives, ou la recherche de photographies sur Google Image, ne peut se traduire que par un enrichissement des possibilités de la recherche. Un autre résultat, certainement plus intéressant, concerne la manière dont les faux négatifs et les faux positifs ont révélé des biais, des surdéterminations et des potentialités propres à un moyen de recherche encore naissant, mais susceptible de gagner en importance. Les notes de bas de page suivantes constituent un catalogue provisoire de ces méconnaissances dans la perspective de les convertir en corrections, révisions et compléments à la boîte à outils de la recherche contemporaine. Enfin, pour initier le processus de réflexion sur ce que signifie faire de la recherche en collaboration avec nos machines cognitives contemporaines, certaines des descriptions taxonomiques ont été générées par ChatGPT et Google Bard.
-
L’entraînement des modèles a été effectué par des scientifiques des données de DataPerformers et de Deloitte à Montréal. ↩
-
Dans certains cas, les documents remplacent les dessins comme objets d’étude privilégiés, non pas pour critiquer le culte architectural du dessin, mais plutôt en raison d’une croyance erronée en leur démonstrativité évidente. Aussi naïve soit-elle, l’idée que les documents parlent intrinsèquement d’eux-mêmes est renforcée par la prolifération des formes d’accessibilité qui rendent les documents apparemment plus faciles à lire : leur lisibilité est facilitée à la fois par les logiciels d’OCR et par l’idée que leurs qualités matérielles sont moins importantes que celles du dessin et donc que leur « sens » serait moins détérioré par la reproduction numérique. ↩
-
Bien sûr, les arbres sont couramment présents dans les documents repérés par des catégories de sujets comme le jardin ou le paysage, mais l’objectif ici était précisément d’éviter de telles surdéterminations. ↩
Lapsus numériques
Identification d’arbres par un outil de machine apprenante dans Hubert Rohault de Fleury, Élévation, plan et coupe d’une maison commune, 1800-1802. Plume et encre noire sur mine de plomb avec lavis sur papier vergé. DR1974:0002:012:028 R/V CCA.

Identification d’arbres par un outil de machine apprenante dans Mario Asprucci (1789 – 1792), Plan d’un cimetière napoléonien (possiblement dans la Pineta Sacchetti), c. 1800. Crayon, plume, encre et lavis sur papier vergé, 650 x 490 mm. DMC 2607r. Avec l’aimable autorisation de Drawing Matter Collections.

Identification d’arbres par un outil de machine apprenante dans Louis-Hippolyte Lebas (1782 – 1867), Homme abreuvant un cheval dans une fontaine, page d’un carnet de croquis de voyage, 1804. Crayon, mine de plomb, lavis brun et aquarelle sur papier vergé, 205 x 160 mm. DMC 1052.2.10. Avec l’aimable autorisation de Drawing Matter Collections.
Deux erreurs catégorielles ont été commises par l’outil avec suffisamment de constance pour laisser penser à une aporie sous-jacente, l’une favorable à la symétrie, l’autre au réalisme. Ces erreurs sont intéressantes dans la mesure où elles sont révélatrices du traitement qui sous-tend les résultats et en particulier des distinctions entre les biais cognitifs/psychologiques, c’est-à-dire humains, au sein des processus algorithmiques de l’apprentissage automatique, ainsi que les biais technomécaniques. Le biais en faveur de la symétrie se révèle particulièrement marqué dans les plans; même s’il montre une configuration de bâtiment asymétrique, l’outil a planté des arbres dans des arrangements axialement symétriques. Le fait que l’outil n’ait pas planté d’arbres pour produire de la symétrie dans les dessins en perspective semble indiquer que l’abstraction du plan invitait à une certaine forme d’intervention dans le traitement; le manque d’informations incitait à remplir davantage les lacunes perçues et laissait donc de la place à l’imagination projective. Cette dynamique expliquerait également l’inverse : les vues en perspective et en élévation ont été acceptées telles quelles, pour ainsi dire, et n’ont ainsi encouragé aucun agent à combler des informations manquantes. Il ne faut pas en conclure que l’outil était précis lorsque les images étaient naturalistes, mais plutôt que le traitement était moins participatif et moins présomptueux face à certains types d’images.
Ces observations révèlent des failles intéressantes dans les types de collaboration entre les agents humains et non humains qui façonnent les protocoles d’apprentissage automatique. D’une part, comme on le sait, les personnes humaines scriptrices apportent dans leur travail des normes culturelles qui sont intégrées dans le système, par ailleurs automatisé. Ces « contributions » sont particulièrement généreuses lorsque l’information fait défaut et que des interpolations sont, sinon nécessaires, du moins possibles . Dans la mesure où les plans d’architecture sont dépourvus de formes normatives de réalisme naturaliste, ils mobilisent cette dynamique : on pourrait dire que l’impulsion corrective a révélé, comme Claude Perrault l’aurait anticipé, une propension naturelle à rechercher la symétrie chez les êtres humains, inclination qui a donné lieu à un algorithme dominé par une approche de la composition aux allures comiquement beaux-arts2. Étant donné que cette erreur est probablement le produit de biais culturels se manifestant sous la forme de symptômes déguisés en artefacts techniques, elle se présente comme une nouvelle version d’un bon vieux lapsus freudien. La tendance au réalisme, en revanche, semble plutôt dériver de la dépendance des protocoles d’apprentissage automatique à l’égard d’un très grand nombre de photographies. Il est intéressant de noter que de nouveaux protocoles de recherche sont développés autour d’anciens analogues photographiques, au moment même où ils sont remplacés par de nouvelles logiques visuelles, ne serait-ce que parce que le glissement entre les deux génère un fantôme dans la machine qui donne l’impression qu’un inconscient opérationnel est à l’œuvre3. Bien que nous critiquions généralement le contrôle soi-disant insidieux des processus automatiques par la présence de biais humains et donc de dynamiques politiques, la disparition du lapsus freudien et d’autres formes subliminales de production apparaît comme une perte qui mérite à la fois une attitude critique et de résistance.
-
Ce projet a suivi les procédures éprouvées de l’apprentissage automatique : des personnes qui étudient l’architecture à Princeton ont reçu des ensembles d’entraînement préliminaires de dessins numérisés sur lesquels elles ont dessiné des zones de délimitation autour des arbres et ont indiqué la projection du dessin. Ces documents ont été remis aux scientifiques de Dataperformers et Deloitte, qui ont entraîné les données sur un modèle de détection d’objets pré-entraîné basé sur une architecture CenterNet Resnet50. Les résultats ont été examinés par les personnes scriptrices et le CCA qui ont identifié les faux négatifs et les faux positifs, puis les ont utilisés pour perfectionner l’algorithme. Ce processus a été poursuivi au cours de trois itérations, chacune avec un nombre croissant de dessins. Le moment du passage de relais entre l’algorithme et les personnes, qui ont elles-mêmes des domaines d’expertise différents, est, comme dans tout relais, le point le plus vulnérable du processus. ↩
-
Dans son Ordonnance des cinq espèces de colonnes d’après la méthode des Anciens, Claude Perrault identifie la symétrie comme un élément absolu de la beauté. ↩
-
Pour m’en assurer, j’ai interrogé ChatGPT : « Avez-vous un inconscient? ». La réponse a été la suivante : « En tant qu’intelligence artificielle, je n’ai pas de conscience ou d’inconscient de la même manière que les êtres humains. Je suis un modèle de langage développé par OpenAI, programmé pour traiter et générer du texte en fonction des informations et des modèles que j’ai appris lors de ma formation. Je n’ai pas de pensées, de désirs ou de sentiments propres. Je fonctionne uniquement en analysant les données d’entrée et en produisant des réponses basées sur ces données. » [ndt : réponse de ChatGPT francophone] ↩
La taille a son importance
Identification d’arbres par un outil de machine apprenante dans Alvaro Siza, Page 255 du carnet de croquis, janvier 1987. Encre sur papier, 21 x 30 cm. ARCH281777 Fonds Alvaro Siza, CCA. Don d’Alvaro Siza. © Álvaro Siza

Identification d’arbres par un outil de machine apprenante dans Le Corbusier (1887 – 1965), Étude du site du stade de Roland Garros, c. 1958 - 1961. Encre sur calque, 273 x 210 mm. DMC 1183. Avec l’aimable autorisation de Drawing Matter Collections. © FLC – CARCC
L’outil a conforté la prédominance de quelques architectes dont l’importance dans l’histoire de l’architecture était déjà reconnue. Le Corbusier et Álvaro Siza ayant été largement collectionnés par le CCA et Drawing Matter, l’algorithme disposait d’un plus grand nombre d’échantillons d’entraînement de leurs idiomes de dessin que de toute autre source clairement cohérente. Grâce à ce vaste ensemble de données, l’algorithme a non seulement appris à discerner les arbres figurant dans leurs dessins avec un degré de précision relativement élevé, mais il a également entrepris d’imposer cet idiome à d’autres comme une valeur positive. Si les dessins ne présentaient pas d’arbres à la manière de Siza, l’outil était plus enclin à ne pas les identifier, convertissant son échec en une reformulation du succès de Siza. En d’autres termes, plutôt que de promouvoir la neutralité à l’égard des figures de proue de la discipline et des structures auctoriales, nous apprenons à nos ordinateurs à renforcer ces attributs par la conversion de la personnalité autrice en ensembles volumineux de données. L’inverse est aussi possible : en égalisant les entrées, la courbe d’apprentissage qui en résulte pourrait être plus largement répartie entre les protagonistes qui ne sont pas déjà en surreprésentation au sein de nos collections et de nos catalogues.
La taille n’a pas d’importance
Identification d’arbres par un outil de machine apprenante dans Adolfo Natalini (1941 – 2020), ‘Il Muro di Firenze, Resturo doppo il Poggi’, croquis du projet Continuous Monument, 1969. Plume et encre sur papier (carnet de croquis), 75 x 250 mm. DMC 2083.18. Avec l’aimable autorisation de Drawing Matter Collections. © Superstudio
Identification d’arbres par un outil de machine apprenante dans John Hejduk, Croquis avec annotations pour Victimes II, 1993. Encre sur papier, 28 × 22 cm. DR1998:0130:032 John Hejduk fonds, CCA. © CCA
En recherchant des pixels structurés selon ce qu’il apprend à définir comme un motif arboricole, l’opération de balayage de l’outil est indifférente au nombre de pixels nécessaires pour constituer un exemple unique digne d’être appris. Ainsi, la taille de la représentation d’un arbre par rapport à la taille du dessin dans son ensemble, ou le fait que l’arbre soit dessiné à l’échelle ou hors échelle en relation avec d’autres objets, n’ajoutent ni n’enlèvent rien à la capacité de l’outil à effectuer une détermination. De fait, l’outil a détecté la présence de très petits arbres, ou d’éléments minuscules qu’il a identifiés comme des arbres, qui m’avaient échappé. Il me semble qu’il est toujours bon d’apprendre à ne pas se laisser impressionner par la taille.
Vers l’hominisation
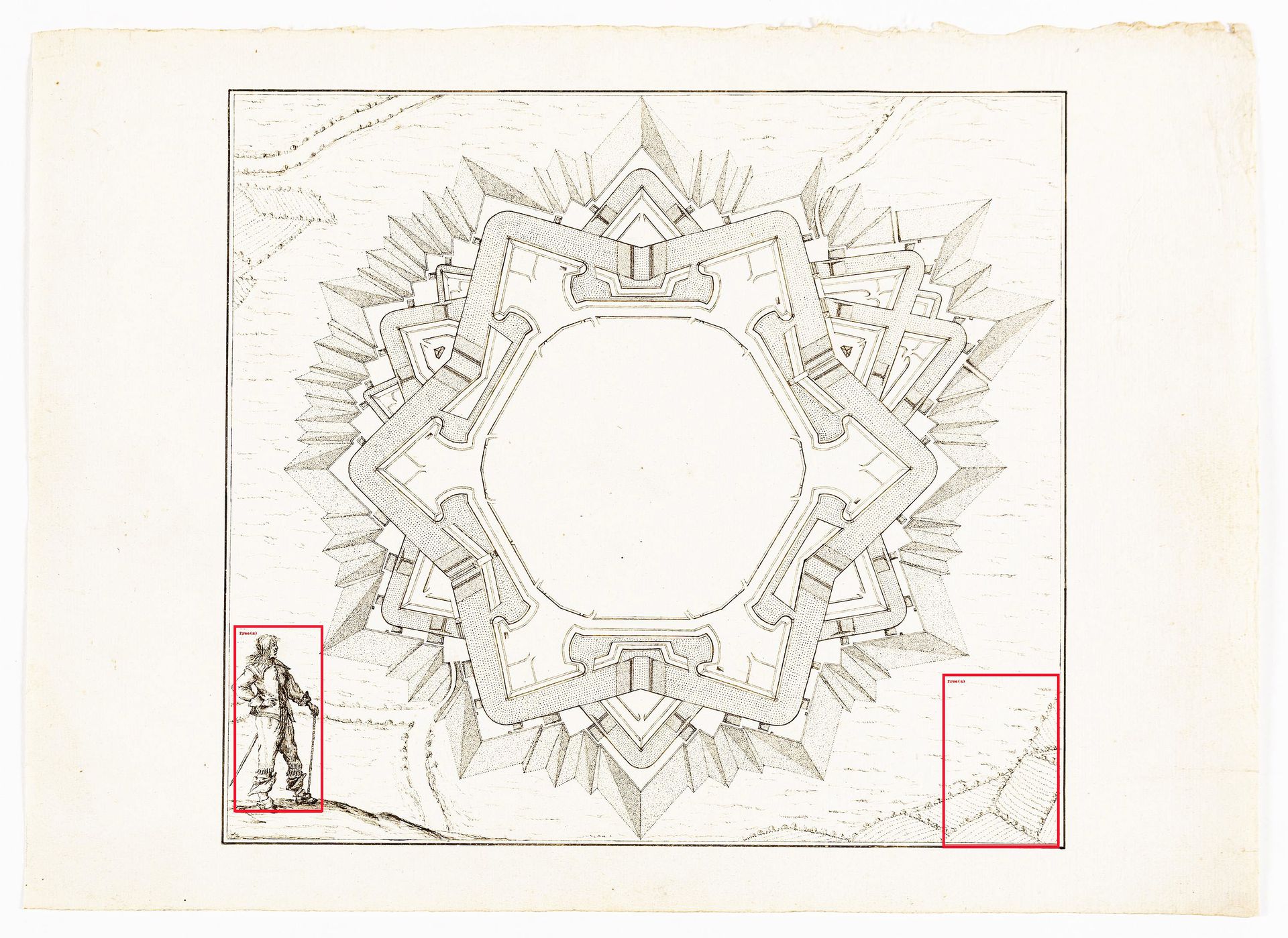
Identification d’arbres par run outil de machine apprenante dans Anonyme, Fortification bastionnée dans un paysage en perspective avec un personnage masculin, c. 1650 - 1720. Plume et encre sur papier, 295 x 408 mm. DMC2572.1. Avec l’aimable autorisation de Drawing Matter Collections.
L’outil a régulièrement confondu les personnes et les arbres. Selon Google Bard, ce phénomène s’explique par le fait que « les protocoles d’apprentissage automatique sont souvent entraînés sur des bases de données comprenant à la fois des personnes et des arbres. Le protocole peut ainsi apprendre à associer certaines caractéristiques aux personnes et aux arbres, comme la présence de cheveux ou de feuilles »1. Il se peut aussi que les protocoles d’apprentissage automatique aient intégré l’impulsion hominisante de la plupart des formes d’exploration moderne et considèrent donc la « découverte » de pixels structurés de manière à affirmer la priorité de la forme anthropomorphique comme un résultat intrinsèquement positif. Dans ce contexte, le fait de souligner que la cabane primitive valorise le pouvoir de croissance de l’architecte et non les arbres utilisés pour la fabrication du bâtiment est moins une erreur ou un faux positif que le fruit d’une herméneutique accidentellement critique.
-
La question précise posée au chat Google Bard était la suivante : « Pourquoi un protocole d’apprentissage automatique peut-il confondre les personnes et les arbres? ». La réponse a été modifiée pour des raisons de longueur. ↩
La croissance de la matière organique

Identification d’arbres par un outil de machine apprenante dans Antoine Lafréry (éditeur), Perspective de l’arc de Titus, Rome, imprimé en 1548. Gravure sur papier vergé, 49.5 x 38.9 cm. DR1979:0255 CCA.
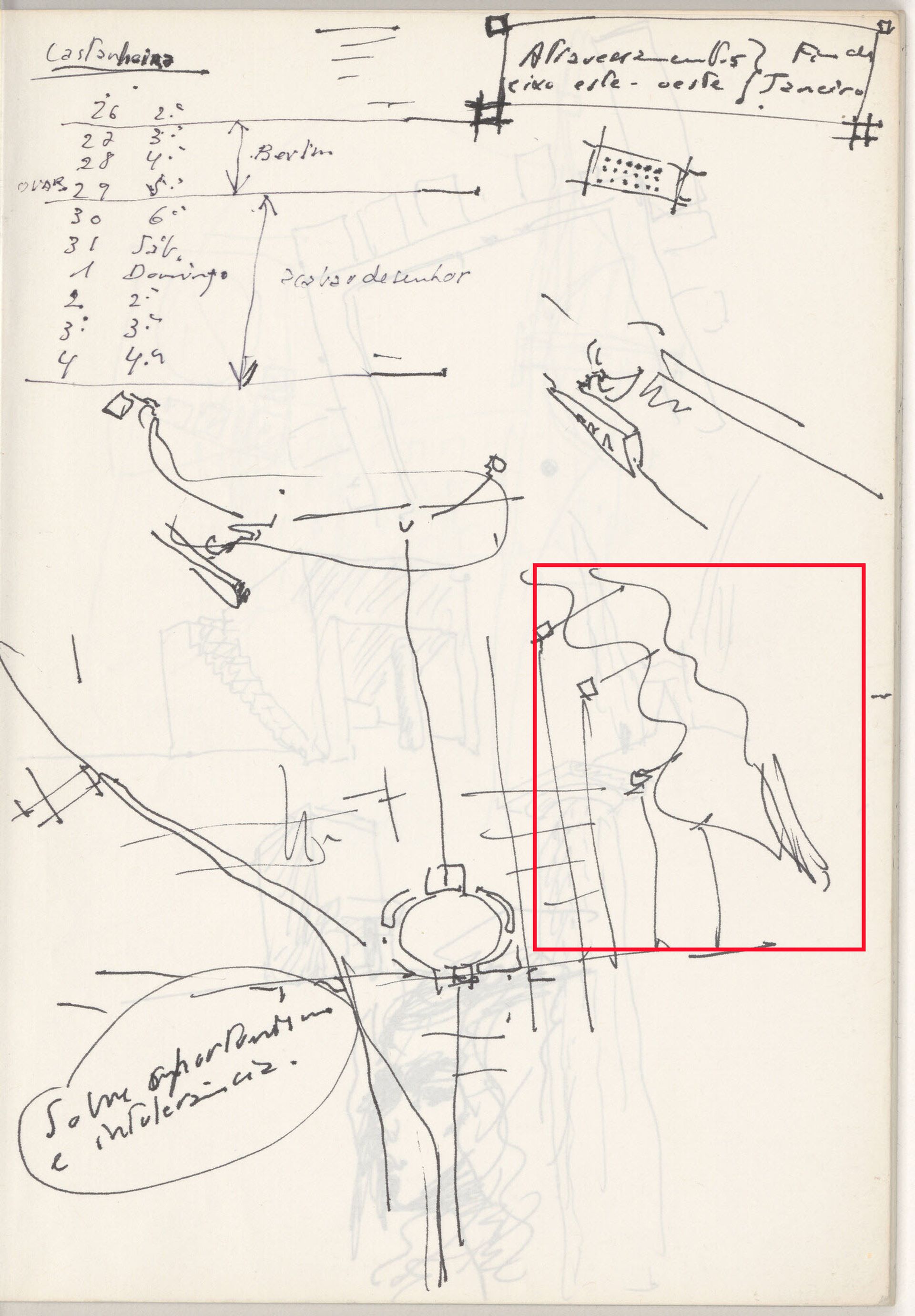
Identification d’arbres par outil de machine apprenante dans Alvaro Siza, Page 166 du carnet de croquis, décembre 1983. Encre sur papier 21 x 30 cm. ARCH281742 Fonds Alvaro Siza, CCA. Don d’Alvaro Siza. © Álvaro Siza
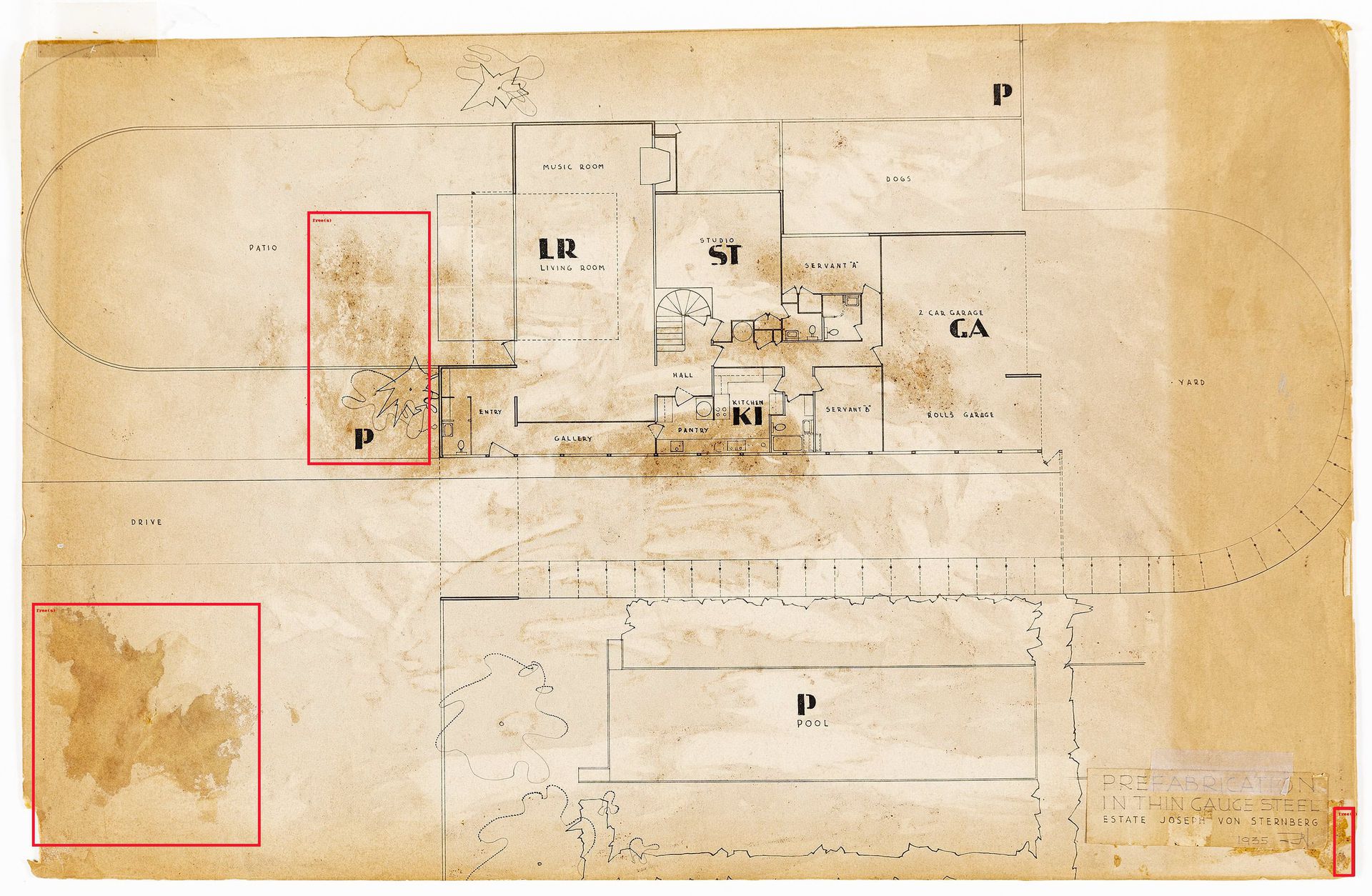
Identification d’arbres par un outil de machine apprenante dans Richard Neutra (1892 – 1970), Plan de la résidence de Joseph von Sternberg, 1935. Encre et crayon sur papier monté sur panneau, 584 x 375 mm. DMC 1277. Avec l’aimable autorisation de Drawing Matter Collections. © Neutra Institute for Survival through Design

Identification d’arbres par un outil de machine apprenante dans Carlo Marchionni (1702 – 1786), Étude en perspective d’un arc de triomphe, Palazzo Albani, c. 1767 - 1769. Encre sépia sur papier, 300 x 210 mm. DMC 1058. Avec l’aimable autorisation de Drawing Matter Collections.
L’outil a bien appris que les architectes dessinent habituellement les arbres – que ce soit en plan, en coupe, en élévation ou en perspective – en se concentrant sur la cime et en la représentant par un contour circulaire grossier et irrégulier. Si l’omniprésence de cette convention graphique témoigne d’une méconnaissance des particularités des espèces d’arbres et peut indiquer, dans l’histoire de l’architecture, une ignorance plus générale de toute une série de particularités environnementales, elle démontre également les multiples façons dont la matière organique et ses modèles de croissance vivent dans les matériaux qui servent de substrat au terrain. Par exemple, l’outil a confondu la voûte des arbres avec les courbes des nuages parce qu’ils sont souvent dessinés comme des motifs quasiment indiscernables. Cette présence graphique conventionnelle est par ailleurs confortée par une absence graphique conventionnelle parallèle. La terre dans laquelle poussent les arbres et l’atmosphère dans laquelle se forment les nuages sont généralement signalées dans les dessins d’architecture par le néant, ou plutôt par le contexte et rien d’autre : elles apparaissent sans matérialité concrète, simplement comme la surface du substrat matériel du dessin. Ces abstractions architecturales courantes et ces formes de négligence ont toutefois permis à la machine de continuer à appliquer la théorie architecturale des modèles morphologiques organiques sans distinction et sans prêter attention aux indices contextuels, jusqu’à ce qu’elle tombe sur des traces de mouvements d’autres médias élémentaires au sein des archives. Pour l’outil, les dessins d’arbres et de nuages et les résidus indexés de moisissures et de taches d’eau sont tous interchangeables, ce qu’ils sont en réalité au sens de la théorie des médias environnementaux.
Narration numérique

Identification d’arbres par un outil de machine apprenante dans Joseph-Charles-Dominique Eisen (1720 – 1778), « La cabane primitive », Essai sur L’Architecture, c. 1755. Dessin pour le frontispice de l’Essai sur L’Architecture de Laugier, vers 1755. Plume, encre et lavis gris sur papier, 154 x 92 mm. DMC 1240. Avec l’aimable autorisation de Drawing Matter Collections.
Jeune architecte, Lily a toujours eu une fascination pour les arbres. Elle aimait la façon dont ils surplombaient le monde, s’élevant vers le ciel, et le sentiment de calme et de paix qu’ils semblaient incarner. En grandissant, sa passion pour les arbres s’est transformée en quelque chose de plus sombre, de plus sinistre. Lily a commencé à passer davantage de temps dans le parc, assise sous les arbres à écouter leurs murmures. Elle en vint à se persuader qu’elle n’était pas seulement une architecte, mais aussi un arbre. Elle passait souvent des heures à fixer les branches, perdue dans ses propres pensées.
Un jour, quelque chose changea. Tandis qu’elle était assise sous un grand chêne séculaire, elle ressentit une douleur aiguë lui traverser le corps. C’était comme si l’arbre avait tendu la main et l’avait attrapée, ses racines s’enfonçant dans sa peau et la tirant vers le bas, dans la terre. Sa peau prit une teinte verdâtre et ses mains devinrent noueuses et tordues, semblables aux branches. Ses doigts fusionnèrent, formant une texture rugueuse proche de l’écorce, ses pieds s’enracinèrent dans le sol, l’empêchant de bouger. Lily entendait les murmures des arbres autour d’elle, de plus en plus forts et insistants au fil des jours. Ils lui parlaient dans une langue qu’elle ne comprenait pas, lui confiaient des secrets et la poussaient à faire des choses qu’elle savait pertinemment ne pas devoir faire. Le lendemain matin, alors que le soleil se levait sur le parc, les arbres autour de Lily frémissaient au rythme de la brise, leurs branches s’étirant comme des doigts crochus. Au milieu d’eux, une seule personne se tenait debout, immobile et silencieuse, son corps tordu et transformé en quelque chose qui n’était plus tout à fait humain1.
-
Cette histoire a été écrite par ChatGPT en réponse aux requêtes suivantes dans cet ordre : expliquer la différence entre un véritable arbre et un faux; écrire une histoire sur une architecte qui se prend pour un arbre; écrire une histoire d’horreur sur une architecte qui se prend pour un arbre. Les réponses ont été éditées pour des raisons de longueur. ↩
Nous remercions tout particulièrement Elspeth Cowell (Chef, Médias numérique, CCA), Zied Touzani (Deloitte), Emad Takla (Deloitte), Matt Page (Directeur adjoint de la Drawing Matter), et les étudiants suivants de Princeton University, Christina Moushoul (chef de projet), Reese Greenlee, Joey Guadagno, Kajsa Souter, Ana Morris, and Sophia Solganik.